01-机器学习概述¶
什么是学习¶
学习的整个过程应该包括输入,处理,输出,反思。比如说,读书,思考,应用到实际,再反思。
学,输入;习,实践。
为什么要学习¶
人类要生存,每时每刻遇到的问题和发生的事件,都是不确定的,未知的。
无法提前给出所有的问题的解决办法,我们需要学习出来一种解决问题的模型,套用模型就可以解决未知的问题。
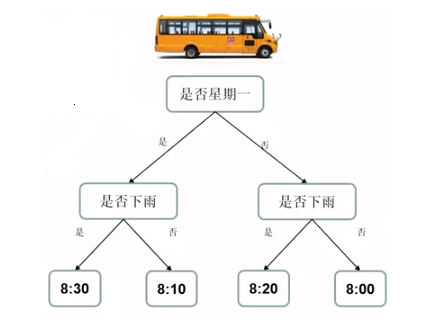
通过旧的问题和答案,学习出来规律;
应用规律去解决新的问题,得到新的预测。
预测班车到达时间, 7点30出发 从A--->B, 预测到B地的时间。 第一次乘车,预测不太准, 但是随着你经验的增加,预测的会越来越准。
机器学习¶
让机器具有自我学习的能力,程序的执行结果跟机器获取的数据量有关,增加新的输入数据,可以生成新的模型,最终程序执行的结果(预测的结果)会发生变化。
机器学习实际上包含很多种数学方法,利用统计学和概率论,信息论等知识,利用已知的数据,创建一种模型,最终利用这种模型进行预测。

机器学习:用大量数据进行训练,获取到一个数据模型,预测就是应用训练的模型,来解决一个未知的问题.
学习方法¶
试着去理解原理,通过结果,理解数学背后的原理,我们是为了解决实际问题,才使用的数学 避免抽象数学和理论数学。
对于数学公式,用实际案例去理解计算过程(算法工程师,软件工程师),不畏惧算法,不畏惧论文 不对公式进行数学证明,靠编写程序直接验证
算法工程师,我知道为什么但不知道这么做
软件工程师,我知道这么做但不知道为什么
我们:算法工程师 +软件工程师
机器学习步骤¶
- 确定与问题相关的数据(明确输入)
- 收集与问题相关的数据 (数据准备,学)
- 分析预测结果的类型 (分类,回归,是判断题还是应用题)
- 根据预测结果的类型,选择一个合适的算法(套路),找到输入和输出之间的关系
- 用这个算法(套路)去解决新的问题 (习)
市面上的很多机器学习相关的课程都是从第三个步骤开始的, 其实在实际开发中1,2两个步骤是非常非常重要的
feature和label¶
自变量和因变量
feature,自变量(输入)
label,因变量(输出)
label = f(feature)
经济损失 = f(地震等级)
分类和回归¶
-
分类: classfication, 数据结果往往是离散的
-
根据你的学习努力情况,判断是否能够通过考试
-
根据email的内容,判断是否是垃圾邮件
-
回归:regression , 数据结果往往是连续的
- 基于车的品牌,年代,型号,预测车的价值(500RMB~500000RMB)
- 基于每天的卡路里摄入量和运动量,预测一周后的体重(48KG~80KG)
- 基于树的直径,预测树的年龄(0~500岁)
机器学习步骤注意事项¶
- 输入输出,就是自变量和因变量,对应feature和label
- 数据集必须是规范,格式统一的,方便计算机程序处理
- 分类的问题答案是有限个,可以理解成选择题和判断题,回归的问题,答案不能用简单的分类来描述
- 确定feature和label之间的关系,有无数种的算法,每种算法都有自己的优缺点。
- 根据预测的情况,我们可能需要重新调整算法和生成的模型