多分类和图像识别
手写数字识别¶

多分类问题. 多分类逻辑回归来解决.
输入(feature) ,图片像素点
输出(label) 0~9的数字
多分类问题
数据格式和灰度图¶
灰度图片示例¶

编程目标¶
多分类问题:
784个参数+一个bias, 生成一个概率输出
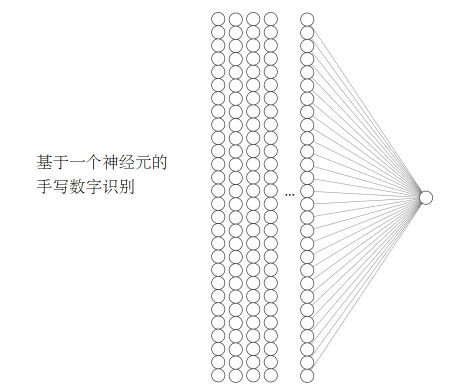
http://alexlenail.me/NN-SVG/index.html
y = m_1*x_1+m_2*x_2+m_3*x_3+...+m_{784}*x_{784}+b
图像数据读取¶
import numpy as np
feature = np.loadtxt('test_image.csv',delimiter=',')
feature[0]
数据图像可视化¶
import matplotlib.pyplot as plt
%matplotlib notebook
plt.imshow(feature[3].reshape(28,28))

自己做数据集的步骤¶
- 手写数字
- 拍照
- opencv缩放到28*28
- opencv转为灰度图片,生成28*28的像素点值
- 打标签
- 重复上述步骤,收集6万个训练数据,1万个测试数据
one-hot encoding 独热编码¶
label = np.array([1,2,1,2,3,4,5,6,7,8,9,0])
np.eye(10)[label]
array([[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 1., 0., 0., 0., 0., 0., 0., 0.], [0., 1., 0., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 1., 0., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 1., 0., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 1., 0., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 1., 0., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 1., 0., 0.], [0., 0., 0., 0., 0., 0., 0., 0., 1., 0.], [0., 0., 0., 0., 0., 0., 0., 0., 0., 1.], [1., 0., 0., 0., 0., 0., 0., 0., 0., 0.]])
#普通写法
# 创建一个顺序模型
model = tf.keras.models.Sequential()
# 第一层 两个输入的数据 一个输出的数据
model.add(tf.keras.layers.Dense(30, input_shape=(64,)))
model.add(Activation('relu'))
model.add(Dense(10))
# 第三层 激活函数
model.add(tf.keras.layers.Activation('softmax'))
model.summary()
# 编译模型,添加优化器,损失函数和评估方法
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, batch_size=64, epochs=40, validation_data=(X_test, y_test))
model.predict(X_test[0].reshape(1,64))
fig = plt.figure(figsize=(3,3),dpi=10)
plt.imshow(X_test[2].reshape(8,8),cmap='gray')
model.predict(X_test[2].reshape(1,64))
如何判断参数是好的呢¶
如何评价模型的好坏?
如何评价一个学生的学习效果, 每日作业(训练),期末考试(测试)
过拟合和欠拟合¶
过拟合:泛化能力不强, 训练集预测数据准确性不错
欠拟合:训练集预测数据准确性不足

模型评估¶
模型accuracy只是评估模型的一种途径,在不同的应用场景下,需要考虑特殊的评估因素
评价指标与概率计算¶
小明怀疑自己得了一种严重的疾病, 这种疾病在人群的发病率为1/10000 , 小明来到医院去做检查,
这种检查的准确率为99% , 小明得到了一个阳性的检查报告。
- TRUE POSITIVE 预测正确,阳性, 有病阳性 TP
- TRUE NEGATIVE 预测正确,阴性, 没病阴性 TN
- FALSE POSITIVE 预测错误,阳性, 没病阳性 FP
- FALSE NEGATIVE 预测错误,阴性, 有病阴性 FN
所以检查报告的情况只有这四种:
- 检查阳性, 且 有病
- 检查阳性, 且 没病 : 假阳性
- 检查阴性, 且 有病 : 假阴性
- 检查阴性, 且 没病
现在小明拿到了检测报告, 阳性的事情已经发生了。
有病 + 阳性的概率 p_1=1/10000*99/100= 99/1000000
没病+ 阳性的概率 p_2=9999/10000*1/100=9999/1000000
其实小明真的得病的概率$ p = p_1/(p_1+p_2) = 99/(99+9999)=0.0098$
其他模型评估公式¶
查全率 召回率Recall = \dfrac {True Positives}{TruePositives+False Negatives}
精确度Precsion = \dfrac {True Positives}{TruePositives+False Positives}
F-score=\dfrac{2*Recall*Precsion}{Precision+Recall}
思考题: 垃圾邮件和疾病 分别适合哪种评估公式?
实践¶
| 是不是有病 | 实际值(actual) | 预测值 | 预测是否正确 |
|---|---|---|---|
| 不是 | 0 | 1 | × |
| 不是 | 0 | 0 | √ |
| 不是 | 0 | 0 | √ |
| 不是 | 0 | 0 | √ |
| 不是 | 0 | 0 | √ |
| 是 | 1 | 1 | √ |
| 是 | 1 | 1 | √ |
| 是 | 1 | 1 | √ |
| 是 | 1 | 0 | × |
| 是 | 1 | 0 | × |
## 混淆矩阵
| 实际(有病) | 实际(没病) | |
|---|---|---|
| 测试(有病) | 3 TP | 1 FP 假阳性 |
| 测试(没病) | 2 FN 假阴性 | 4 TN |
准确率: 总样本中预测正确的有几个 7/10 , 最常见的评价指标
精确度: 也叫查准度 , 3/ 4
召回率: 也叫查全率 , ⅗
模型评估代码¶
from tensorflow.keras.models import load_model
classifier = load_model('abc.h5')
# 混淆矩阵
from sklearn.metrics import classification_report,confusion_matrix
#预测值
y_pred = classifier.predict_classes(x_test)
print(classification_report(np.argmax(y_test,axis=1),y_pred))
print(confusion_matrix(np.argmax(y_test,axis=1),y_pred))
# 把哪些预测错误的信息, 都提取出来
import numpy as np
result = np.abs(np.argmax(y_test,axis=1)-y_pred)
errorarray = np.nonzero(result>0)
errorarray
init_printing(pretty_print=True)