卷积神经网络
CNN入门¶
为什么需要cnn¶

看你还是看右, 你的脑子在跳跃。
我们大脑看feature 来进行特征识别, 看左和看右是不一样的感受。

多个特征,脑子不能决定,心里好憋的慌。
神经网络处理图片的过程和我们人类是非常类似的。
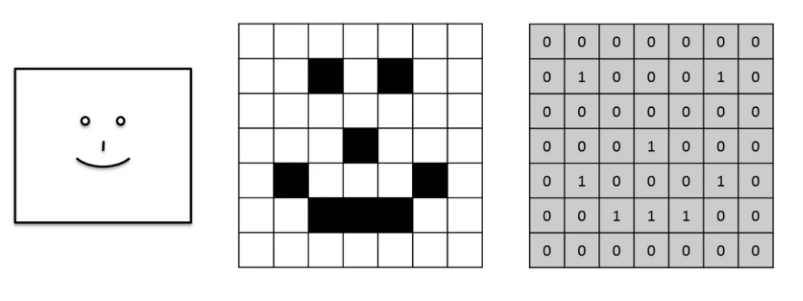
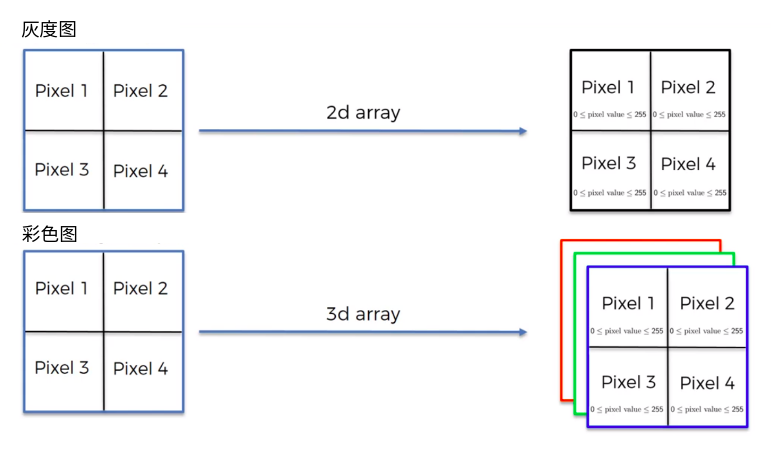
什么是卷积和图像特征¶
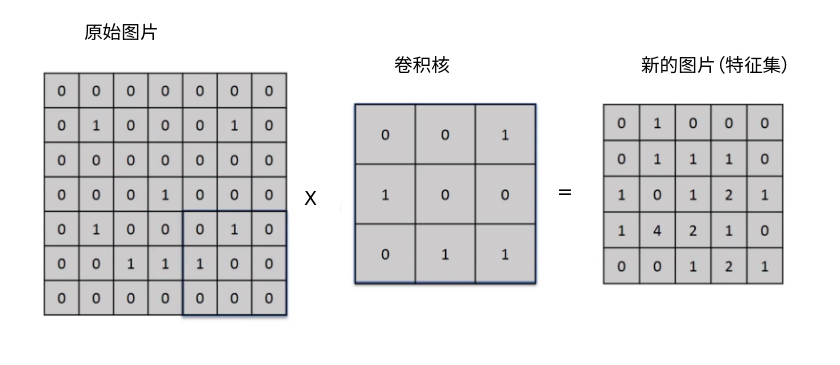
回顾opencv的卷积核,卷积核准确的讲叫特征提取器



import matplotlib.pyplot as plt
import pylab
import cv2
import numpy as np
img = plt.imread("a.jpg")
plt.imshow(img) #显示原图
pylab.show()
fil = np.array([[ 1,1,1], #卷积核
[ 1,1,1],
[ 1,1,1]])
res = cv2.filter2D(img,-1,fil) #使用opencv的卷积函数
plt.imshow(res) #显示卷积后的图片
pylab.show()
卷积的过程复习¶

- stride 步长 ,步长越大,数据量压缩的越多
-
depth 多少个特征提取器,分多少层
-
padding 是否补齐数据
卷积的目的¶
- 减少了图像的数据量。make the image smaller,train faster 64 x 64 x 3 = 12288 如果是普通的图片呢? 1920 x 1080
- 增强了feature, 鼻子,眼睛,头发等,这些是feature,人并不是处理所有的信息的,人只处理特征值
- 卷积神经网络的目标之一, 通过训练,寻找合适的卷积核,用来侦测不同的feature
- 强化关键信息,弱化无关数据
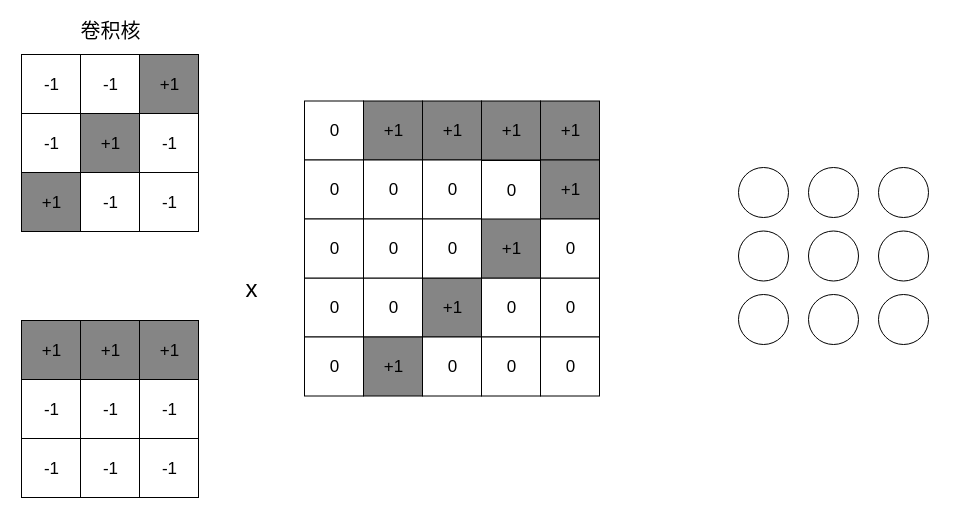
卷积核与图像特征¶
高斯卷积核,模糊卷积核,中值卷积核...这些都是人通过看规律找到的,cnn的作用就是让神经网络自己找合适的卷积核,具体的可视化,我们后面通过代码给大家来查看。
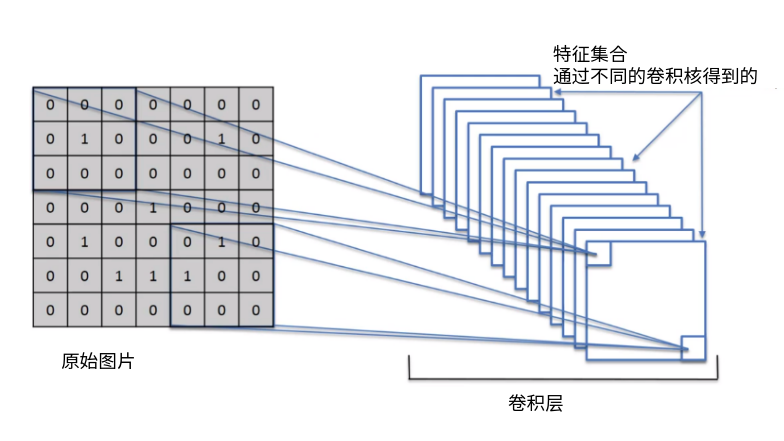
卷积核的设计¶
卷积核设计的几个考虑因素
- 卷积核大小 kernel size
(几乘以几的卷积核呀)
- 深度 depth
深度不是图片的rgb深度, rgb都是3层的, 每一层识别不同的特征
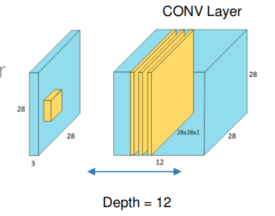
- 步长 stride
默认步长是1, 如果图片比较大可以调大步长
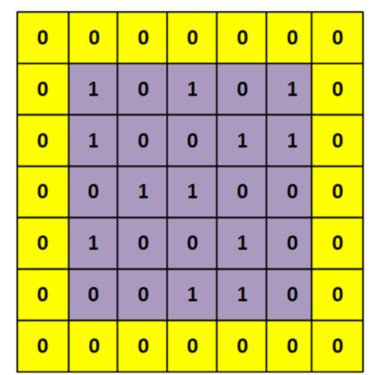
- 填充 padding
避免卷积后,图像大小变小, 一般用zero-padding
卷积后图像大小计算公式¶
- 卷积核大小 K
- 步长 stride S
- 填充 padding P
- 原始图像大小 I
除不尽只保留整数位
(I + 2P - K) / S + 1
例如: 图像5x5的 卷积核3x3 填充1 步长1 (5+2-3)/1 + 1 = 5
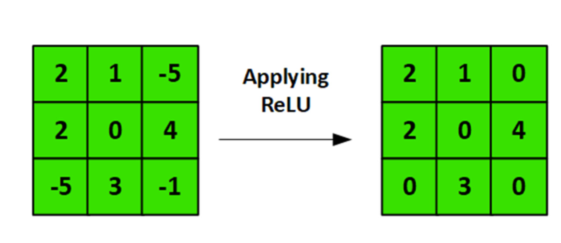
Relu层¶
还记得之前的激活函数吗?
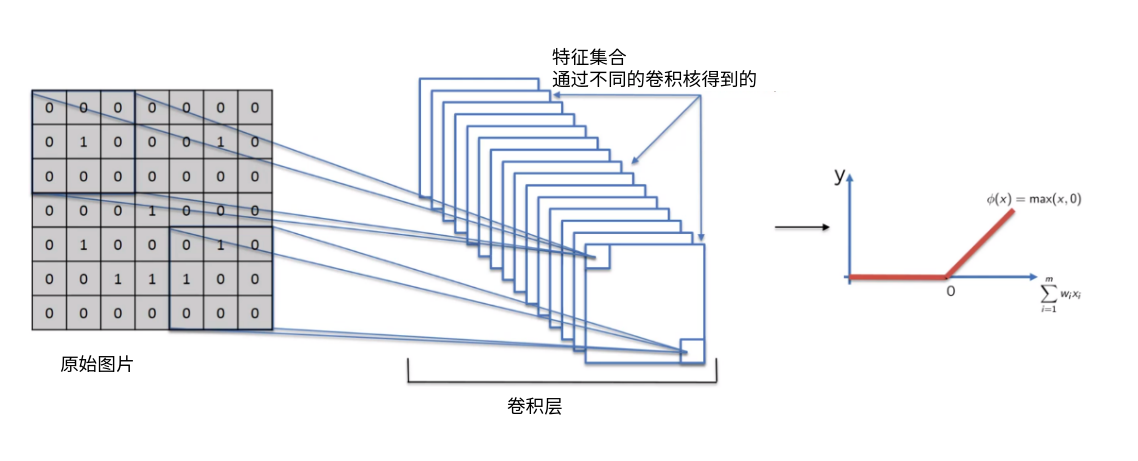
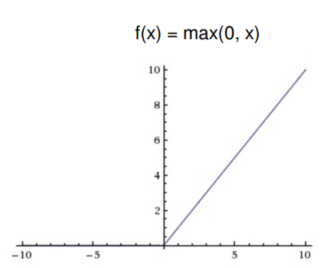
跟激活函数类似,过滤掉低于0的,非法数值。因为图片的像素值小于0 是没有意义的。
卷积后的图像可能会出现负值, relu来解决这个问题
pooling池化¶
池化,max pooling 也叫down sampling,降采样

这些图片大家一看就知道是豹子, 那么怎么教计算机能识别这是豹子呢? 要找到豹子的特征, 豹子实际上由纹理,鼻子,脸部轮廓等很多特征组成,我们要想办法找到豹子在图片熵的位子,豹子脸的朝向,旋转角度等信息。
池化技术就非常的合适。
我们来看一个步长为2的池化操作
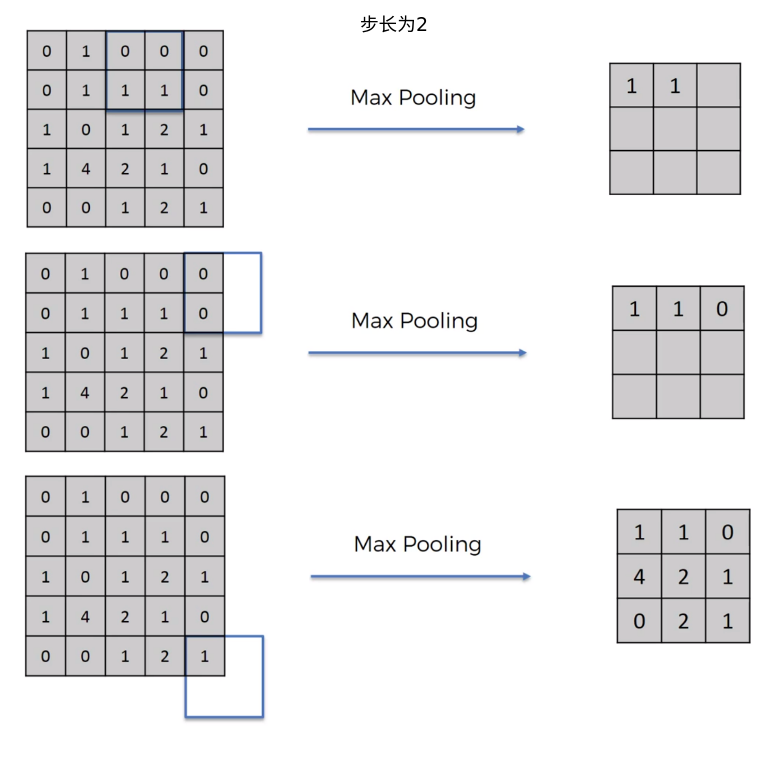
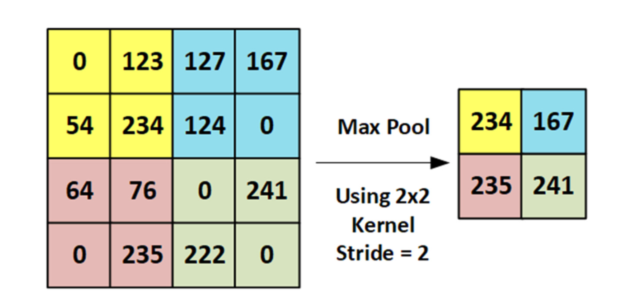
max pooling 是找到若干个点中最大的,把他保留下来。
好处,
-
提炼出了特征点, 即使图片旋转,也不影响特征点的提取
-
降低了过拟合的可能性
-
减少了75%的数据量
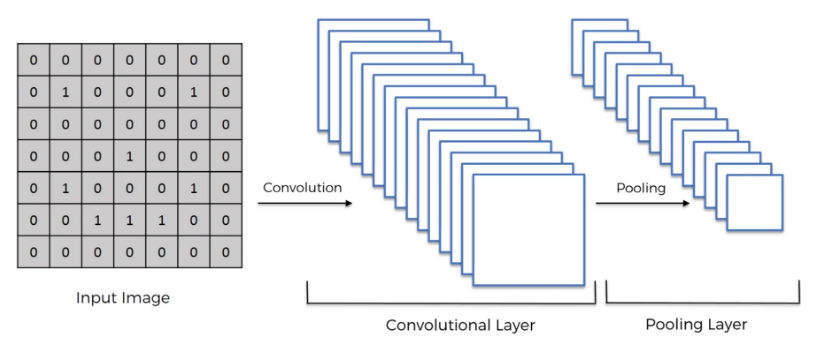
pooling 可以有效降低图像的像素, 降低运算参数的数量.
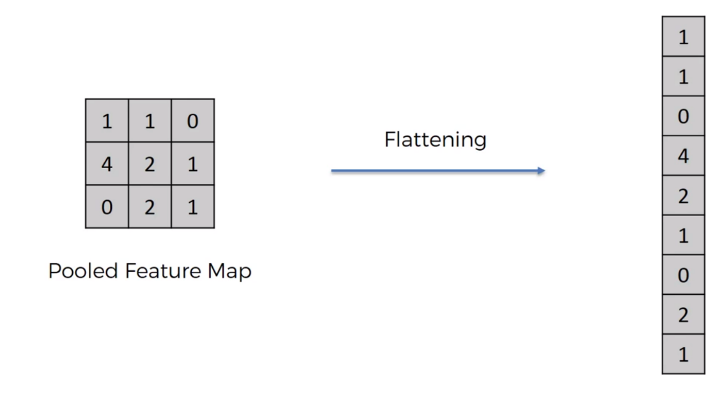
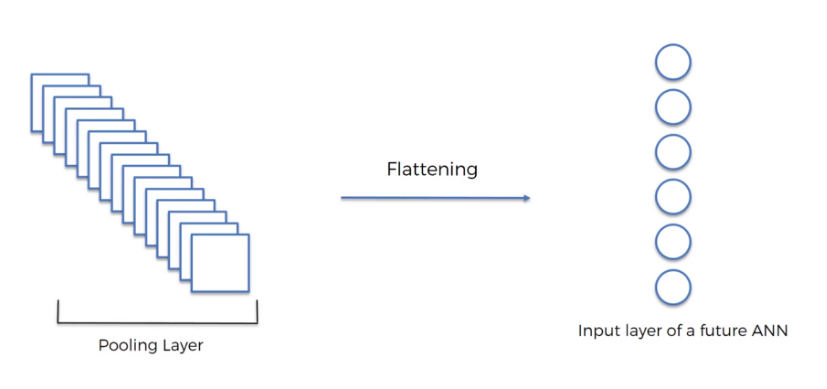
flattening 打平¶
降维打击,把二维的数据用一维数据去表达
Batch normalization¶
batch normalization is used to normalize the activations of a input tensor before passing it into the next layer in the network
model.add(BatchNormalization())
batch normalization的好处:
- 帮助收敛, 减少epochs的次数
- 可以帮助解决overfitting 问题
- 提升训练的稳定性, 对于大一点的学习速率不敏感
缺点:
1. 降低训练速度
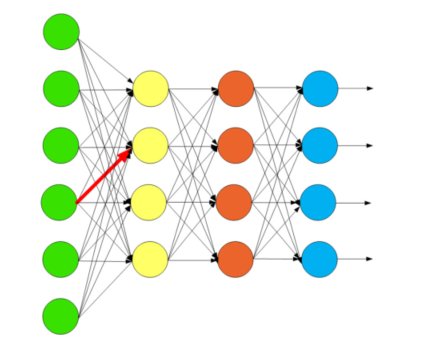
全连接层 FC层¶
fully connected
数据经过处理完毕后, 数据大小减少了,特征明显了,我们可以进一步的交给神经网络来进行训练了
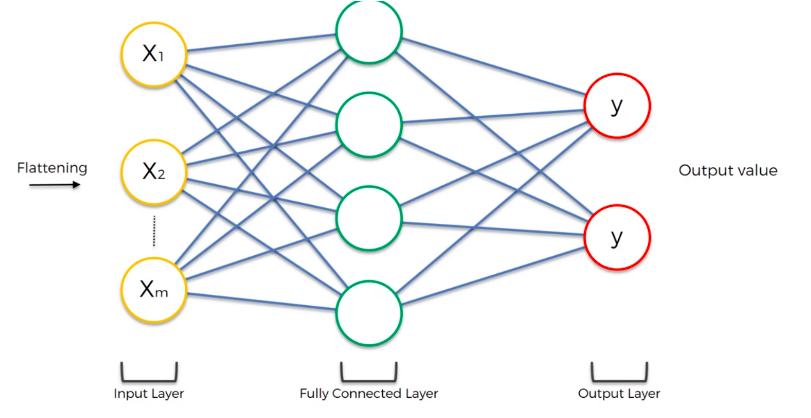
卷积干的事情是什么? 卷积是把特征降维提取出来,然后交给神经网络去处理。
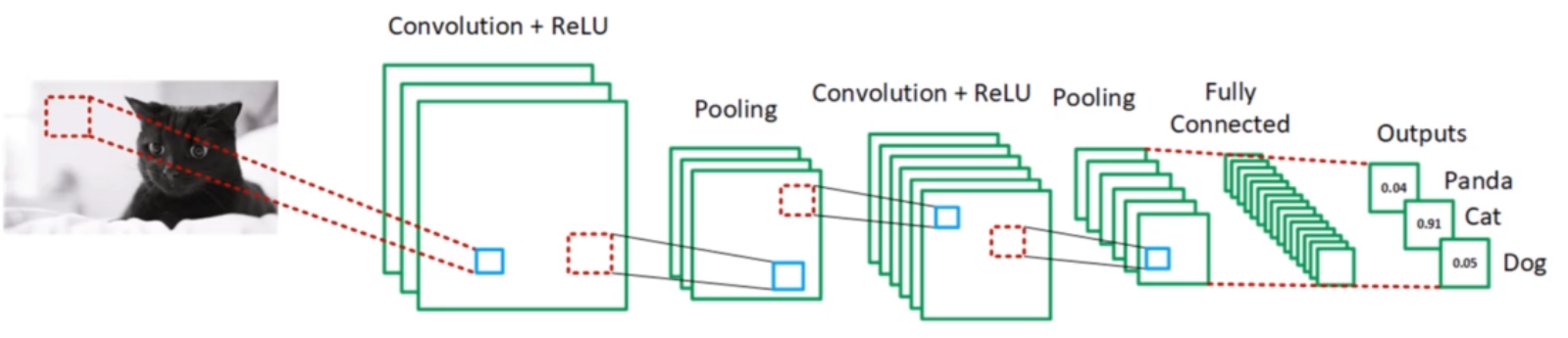
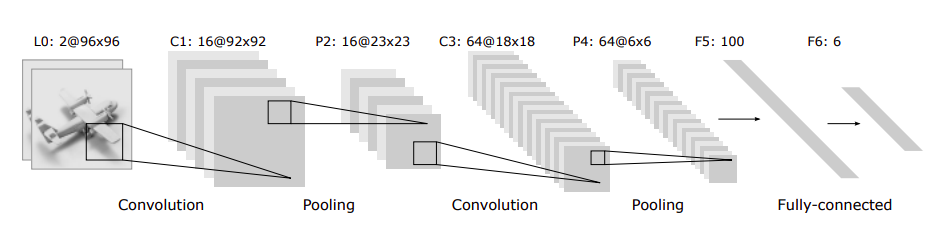
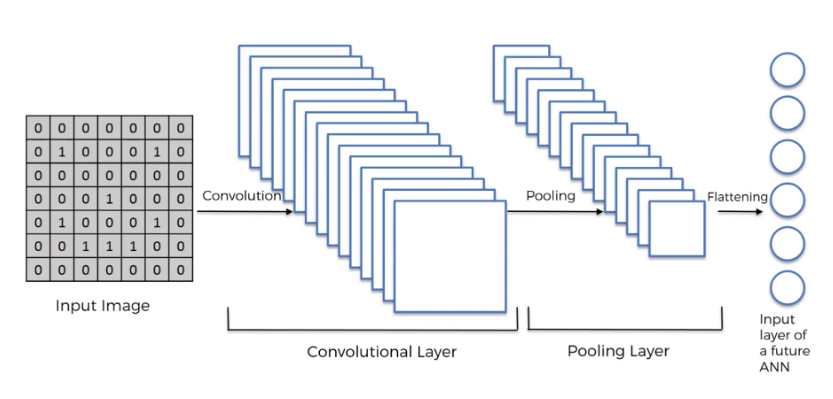
卷积神经网络全景图¶
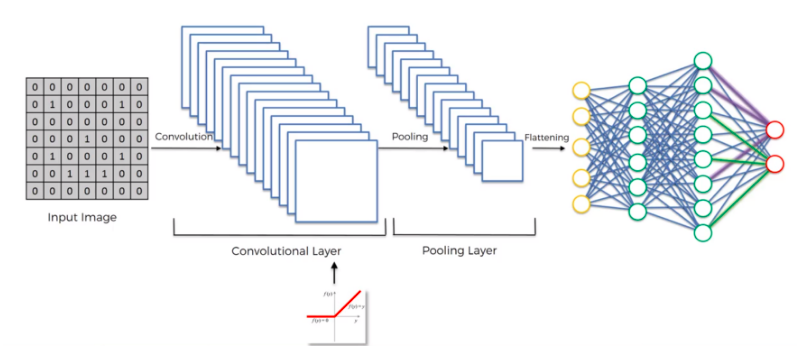
CNN设计¶

- input 层 大小一般为 28x28x1 64x64x3 128x128x3 类似这样的形状, 最好宽高保持一致
- input层大小要能被4整除, 方便下采样
- 特征提取器(卷积核)大小一般为 3x3 或者 5x5
- 步长 stride 一般为1 或者 2(如果图像比较大)
- zero padding可以考虑使用, 如果需要图像大小不变
- 下采样的pool size 一般为2x2, 图像像素量变成原来的¼
- dropout 可以有效防止过拟合
- 层级越多,cnn可以学到的特征就越多
- 通常结构, Input -> Conv -> ReLU -> Pool -> Conv –> ReLU –> Pool -> FC - Output